Download from
http://www.nyangau.org/rep/rep.zip.
Shared Repository provides the following features :-
/dir1/dir2/file.
It doesn't (and probably never will) offer the following :-
byte[]
objects and so must fit into JVM heap memory.
This shouldn't be a big issue for the typical use cases for the
repository, and can be eased somewhat using java -Xmx.
Important: Shared Repository requires that you have a good understanding of the system clocks on the servers on which it runs. Ideally they should be closely synchronized, but if not, there are adjustments you can make.
Shared Repository is useful when there is the requirement to make public reference data (or other infrequently changing data) available in a number of geographically seperate locations, and to allow it to be changed in a controlled manner from any location.
It is especially useful when the reference data is XML based.
A particularly likely use case is where the reference data in question is actually configuration data. Part of the reason for the HTTP interface is an acknowledgement of the fact that it is not unusual for programs to access their configuration by fetching from a URL.
Although probably not a common use case, you could use the Shared Repository
as a way of doing simple static web hosting.
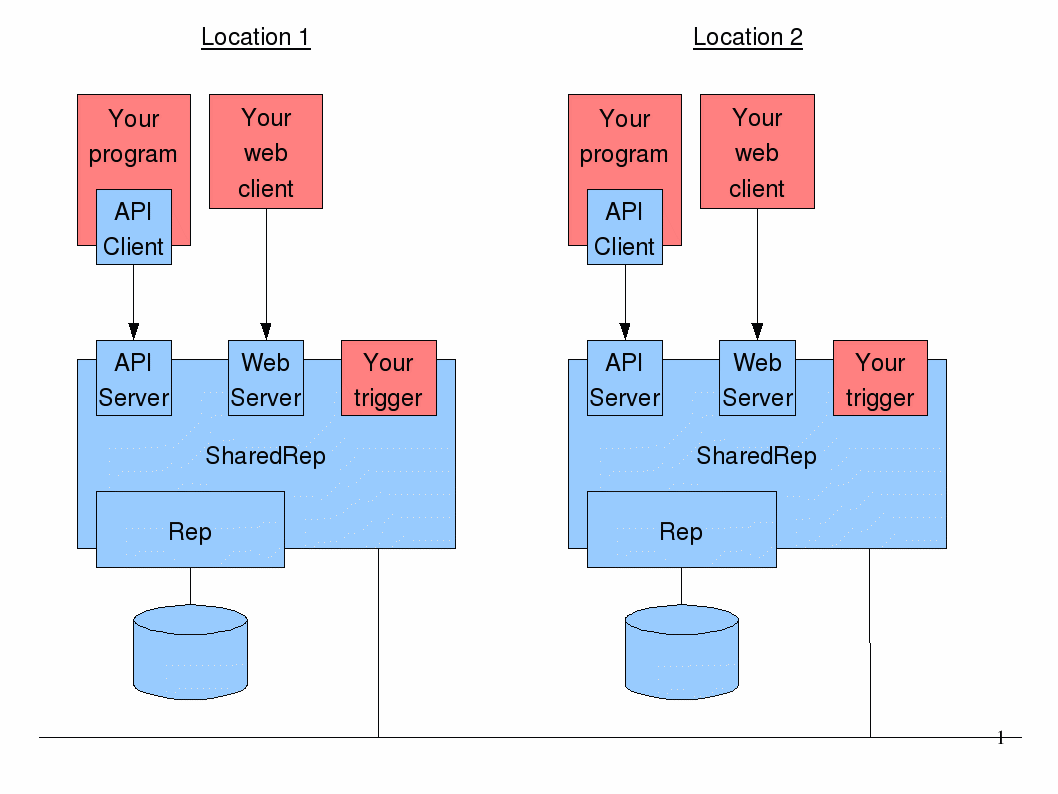
Architecture
Block diagram :-
In the diagram, the Shared Repository is shown in blue. The pink parts are code you would write or acquire to meet your specific business need.
You can deploy in as many locations as you want, but each location must be assigned a unique location number (a positive integer). You'd probably deploy one repository location (instance) in each geographical location and make each deployment highly available by putting its content on shared storage and using clustering software to control where this was accessible from and where the Shared Repository process runs. You'd use floating IP addresses or change DNS to ensure that after failover, each repository location was available by the same DNS name.
Multiple client programs can use the API client to read, write and delete content. Multiple web clients can access content in a repository at the same time too. It would be normal for clients in a given location to access the Shared Repository in that location.
API Client to API Server communication is secure. Access to the API Server is over an SSL encrypted link, and the client supplies a password that the server checks.
In the diagram, Rep is a code module which manages the file store in its location, in such a way as to ensure atomicity of changes. Rep stores content and metadata in this store in a format of its choosing, so don't expect to be able to access the content on the filesystem directly, bypassing the repository.
Your trigger is an optional feature.
You can tell the Shared Repository to instantiate an instance of your
own object, and to notify it when content in the repository is written to,
or deleted.
You therefore have the option to notify any processes in that location
which might need to reload data from the repository.
Content model
The repository contains a set of files, each identified by its name,
typically of the form /dir1/dir2/file.
Directories appear to exist for as long as there are files within them. Directories are never explicitly created or deleted. Essentially, directories are a convenience for navigation purposes. eg: if the repository contains the following files :-
/index.html /xmldocs/authors.xml /xmldocs/dances.xml
the directory /xmldocs appears to exist, containing
authors.xml and dances.xml.
If both .xml files are deleted, the directory no longer
appears to exist
As a somewhat surprising result, a given name in the repository can be both a file and a directory, at the same time. eg: if the repository contained the following files :-
/index /index/pages /index/diagrams
then /index would be a file, and also would appear to
be a directory containing pages and diagrams.
This content model is used so as to ensure the repository never has to
manage the replication of directory creations, modifications and deletions,
and as a result, there are never dependencies between updates to seperate
items in the repository.
ie: the repository only updates files.
If the repository understood directories, and provided verbs such as
mkdir and rmdir, files could presumably only exist
in a directory, after the directory had been created.
This becomes problematic when updates are made independantly in different
locations.
The fact a repository name can refer to both a file and a directory has implications noted later in this document.
Listing the contents of a directory that doesn't exist through the API
isn't an error - the result is a zero length list.
But the isDirectory API will return false,
and you'll get a 404 through the web interface.
The pathname seperators in repostory filenames are always /
and never \ characters, even on Windows.
It is possible to operate the repository in a mode where all filenames are mapped to lower-case. This is to support operation on Windows, where filesystems are case preserving but case insensitive.
Versions of Shared Repository before 0.9 didn't handle filenames
with special characters very well, but this has now been improved.
Cluster definition
Each shared repository has a cluster definition. Here is an example that can be used for testing the software on the local host, which happens to be on a kind of UNIX :-
# # cluster.props - A cluster for testing on the local host # groups=g1 group.g1=0,1,2 location.0.portAPI=6600 location.0.portHTTP=6700 location.0.basedir=content-0 location.1.portAPI=6601 location.1.portHTTP=6701 location.1.basedir=content-1 location.2.portAPI=6602 location.2.portHTTP=6702 location.2.basedir=content-2 verifyHostname=false caseSensitive=true
In this example, there are 3 locations.
They are in a single replication group
called g1.
If a location.N.host is missing, it defaults to
localhost.
If a location.N.portAPI is missing, it defaults to
6600.
If a location.N.portHTTP is missing, it defaults to
6700.
As the locations are on the same host, they've been given different ports.
If a location.N.basedir is missing, it defaults to
content.
As the locations are on the same host, they've been given different
directories.
If a location.N.keystore is missing, it defaults to
SharedRep.jks.
If a location.N.storepass is missing, it defaults to
password.
File permissions should be set to limit access to the keystore and/or
the keystore password should be kept secure.
If a location.N.tAdjust is missing, it defaults to 0.
This is explained in cluster timestamps.
Because the cluster configuration file contains passwords, file system
permissions should be set to limit access to it.
If clusterpass is missing, it defaults to password.
If clusterpass2 is missing, it defaults to the same value as
the clusterpass property.
When one location connects to another, it sends the clusterpass.
The other location checks against both the clusterpass and
clusterpass2, and will allow the connection if either matches.
This mechanism exists to make it possible to change passwords in different
locations at different times, and not require all repositories to be restarted
at the same time :-
clusterpass2 to be the new password value,
and restart at a locally convenient time.
Now each server will accept the new password as well as the old.
clusterpass and
clusterpass2, and restart at a locally convenient time.
Now each server will log into other servers using the new value,
but still accept the old.
Also, in each location change any clients to use the new password.
clusterpass2,
and restart at a locally convenient time.
Now only the new password is accepted.
verifyHostname=false is used because
SharedRep.jks contains a certificate that doesn't have
locahost as its common name (CN=).
In a secure Production environment, each location would define its keystore
to use and keystore password, and the certificate in the keystore would
reflect its the DNS name in the location.N.host property.
verifyHostname=true is the default.
On a Windows system, filesystems preserve case but are not case
sensitive, so we would have to set caseSensitive=false.
As a result all file and directory names put into the repository would be
mapped to lowercase.
In a mixed environment (some locations running on case sensitive UNIX
and some running on case insensitive Windows), every location would have
to use caseSensitive=false.
Note that caseSensitive=true is the default,
so check its set right for your setup before starting your first repository
location.
There is a dirListing property, which can be set to
html (the default) or xml, which controls how
directory listings are returned over the HTTP interface.
A more realistic Production configuration therefore looks like this :-
# # cluster.props - The Production cluster # groups=g1 group.g1=0,1 location.0.host=repo1.company.com location.0.storepass=itsasecret location.1.host=repo2.company.com location.1.storepass=donttell clusterpass=unguessable
where the SharedRep.jks files in each location contain real
root CA and server certificates, whose common names are
repo1.company.com and repo2.company.com.
The server
In this document, to cut down on typing,
assume that run.sh does the following :-
#!/bin/ksh java -Xmx256m -cp nyangau-rep.jar:nyangau-se.jar nyangau.rep.SharedRep "$@"
Here is the usage :-
$ ./run.sh
usage: SharedRep [flags]
flags: -l loc unique location number of this instance
-c props cluster properties file (default: cluster.props)
-t triggerclass classname to trigger (default: none)
Each running instance of the repository needs to know its location number and the cluster configuration file.
So, to run up a couple of locations from the original example cluster,
assumed to be in cluster.props, you could open a shell window
and type :-
$ mkdir content-0 $ ./run.sh -l 0
In another shell window type :-
$ mkdir content-1 $ ./run.sh -l 1
In the example I use -Xmx256m to ensure it has a nice big heap.
The repository server keeps file metadata in memory and also caches some
file data.
JConsole is your friend for tuning this to match your content size.
The command line client
Shared Repostory includes a simple command line client, which can be used to :-
In this document, to cut down on typing,
assume that run_client.sh does the following :-
#!/bin/ksh java -cp nyangau-rep-client.jar -Dnyangau.rep.verifyHostname=false \ nyangau.rep.SharedRepClient "$@"
Run with no arguments to see the usage :-
$ ./run_client.sh
usage: SharedRepClient [flags] cmd {arg}
flags: -c connection connection string (default: srep://localhost:6600)
-P pwServer password, or @file to read from file (default: password)
cmd {arg} command, with arguments
ls name
lsFile name
lsDir name
get name file
getFile name file
getDir name file
put file name
putFile file name
putDir file name
del name
delFile name
delDir name
xpath name pattern recurse content xpath nsctx
name refers to the name of a file or directory in the
repository, and file refers to a file or directory on the
filesystem.
To import the sample files included with Shared Repository into location 0 of the repository started above :-
$ ./run_client.sh put samples / samples/config.properties -I-> /config.properties samples/index.html -I-> /index.html samples/xmldocs/authors.xml -I-> /xmldocs/authors.xml samples/xmldocs/dances.xml -I-> /xmldocs/dances.xml
Because samples is a directory on the filesystem, every file
below it is placed below the / directory in the repository.
If samples had been a file, then the / would have
needed to be replaced by a valid repository filename.
We can list the content (observe that only files are shown) :-
$ ./run_client.sh ls / /config.properties /index.html /xmldocs/authors.xml /xmldocs/dances.xml
Shortly after importing, you will also observe that the same content
is available in location 1 also.
You'd need to pass -c srep://localhost:6601 to point the
client at location 1.
We can export using :-
$ ./run_client.sh get /xmldocs /var/tmp/snapshot /xmldocs/authors.xml -E-> /var/tmp/snapshot/authors.xml /xmldocs/dances.xml -E-> /var/tmp/snapshot/dances.xml
del is like ls, except it doesn't just list
what it finds, it deletes them too.
ls, get and del operate on whatever
they find.
If name refers to a file in the repository, they operate on it.
If name refers to a directory in the repository, they operate
on every file recursively below that.
If name refers to both, and remember this is possible
according to the content model,
they operate on both.
Sometimes this is not desired, so the lsFile, lsDir,
getFile, getDir,
delFile, delDir only operate on a file
or directory in the repository matching the name given.
Similarly putFile and putDir only operate on the
file name given, if it refers to a file or directory.
Having a given name in the repository referring to both a
file and directory is usually an accident.
delFile or delDir can be particularly useful
cleaning this up.
eg: make a mistake :-
$ ./run_client.sh put index.html /index index.html -I-> /index $ ./run_client.sh put indexOfTables.html /index/tables.html indexOfTables.html -I-> /index/tables.html $ ./run_client.sh put indexOfFigures.html /index/figures.html indexOfFigures.html -I-> /index/figures.html
Note that /index is now a file and directory.
To fix it :-
$ ./run_client.sh delFile /index /index $ ./run_client.sh put index.html /index.html index.html -I-> /index.html
To search the repository for an XPath expression, use xpath.
The example below call looks in the root directory,
matching all filenames, recursing into subdirectories, returning the
matched content (not just the names), for a specific XPath, which depends
upon no prefix=namespace mappings.
Namespace mappings can be supplied as a space seperated list of
prefix=namespace tokens, such as
"fish=http://www.foodsales.org/ns/fish
meat=http://www.foodsales.org/ns/meat".
In the example, - is taken to mean null.
With the sample data we loaded into the repository, we would get :-
$ ./run_client.sh xpath / - true true "//dance[@group='latin']" - <?xml version="1.0" encoding="UTF-8" standalone="no"?> <r:files xmlns:r="http://www.nyangau.org/rep"> <r:fileError info="parsing" name="/config.properties"/> <r:fileError info="parsing" name="/index.html"/> <r:fileError info="parsing" name="/test.txt"/> <r:file name="/xmldocs/dances.xml"> <dance beat="4" group="latin" name="cha cha cha"/> <dance beat="4" group="latin" name="rumba"/> <dance beat="4" group="latin" name="samba"/> <dance beat="4" group="latin" name="jive"/> </r:file> </r:files>
Note that some of the files included within the scope of the search
cannot be parsed as XML, and so are returned as
<r:fileError>s.
File errors can also occur with info="decoding" if
the character encoding isn't right (eg: characters are encoded in
UTF-8 form, but the data has <?xml encoding="UTF-16"?>).
Note also that the XML elements created around the results are not in the default namespace, so as to allow you to differentiate between these elements and elements in the returned data with matching names.
In a secure Production environment, you wouldn't be using
-Dnyangau.rep.verifyHostname=false as you'd want the client
to check that the common name in the certificate supplied by the server
matched the DNS name by which you connected to the server.
By default, the client uses SharedRepClient.jks as a
truststore and password as the truststore password.
It is called a truststore (as opposed to a keystore) as it only needs to
contain a root CA certificate, it needn't contain any client or server
certificate signed by that root CA (or any corresponding private keys).
You can direct the client to use a different truststore and password by
setting the nyangau.rep.truststore and
nyangau.rep.storepass system properties.
Given a secure Production repository will be using a keystore with a
reputable root CA and a server certificate signed by it (and corresponding
private key), you'd probably want a Production client to refer to a
truststore with only the reputable root CA in it.
Also, in a secure Production environment, to avoid exposing the cluster
password on the command line, you'd put it in a file (with suitable file
permissions) and use -P @password.file to reference it.
The API
nyangau-rep-client.jar contains the
SharedRepClient class, which is the API Client.
You can put this on your classpath, and invoke methods in it.
The API provided is :-
public class SharedRepClient
{
public SharedRepClient(
String connection, String password, Map<String,Object> env
)
throws FileNotFoundException, IOException;
public SharedRepClient(
String connection, String password
)
throws FileNotFoundException, IOException;
public boolean isFile(String name)
throws IOException;
public boolean isDirectory(String name)
throws IOException;
// can be expensive, use sparingly
public String[] filesInDirectory(String name)
throws FileNotFoundException, IOException;
// returns new String[0] if name isn't a valid directory
public String[] directoriesInDirectory(String name)
throws FileNotFoundException, IOException;
// returns new String[0] if name isn't a valid directory
public long fileModTs(String name)
throws FileNotFoundException, IOException;
// timestamp is a local timestamp, not a cluster timestamp
public byte[] readFile(String name)
throws FileNotFoundException, IOException;
public boolean writeFile(String name, byte[] b)
throws FileNotFoundException, IOException;
public boolean deleteFile(String name)
throws FileNotFoundException, IOException;
public String findXPath(
String name, // can be file or directory
String filter, // can be regexp to match against file basename, or null
boolean recurse, // do subdirectories too
boolean content, // just list matching files, or include content too
String xpath, // XPath expression to use
String nsprefixes // Namespace prefixes, or null
)
throws FileNotFoundException, IOException, PatternSyntaxException, XPathExpressionException;
}
Note that as per the content model, there are no methods to create or delete directories.
Ignoring exceptions, you could write something like this :-
import nyangau.rep.*;
SharedRepClient c = new SharedRepClient("srep://localhost:6600", "password");
if ( c.isFile("/xmldocs/dances.xml") )
System.out.println("found a file");
System.out.println(new Date(c.fileModTs("/xmldocs/dances.xml")));
if ( c.isDirectory("/xmldocs") )
System.out.println("found a directory");
String[] fns = c.filesInDirectory("/xmldocs");
String[] dns = c.directoriesInDirectory("/xmldocs");
c.writeFile("/xmldocs/greeting.xml", "<?xml version=\"1.0\"?><text>Hello</text>".getBytes("UTF-8"));
String xml = new String(c.readFile("/xmldocs/greeting.xml"), "UTF-8");
c.deleteFile("/xmldocs/greeting.xml");
String found = c.findXPath("/", null, true, true, "//dance[@group='latin']", null);
There may be other public methods on the SharedRepClient class,
but these aren't a part of the API - don't use.
The API responds to the same nyangau.rep.* system properties
as shown in the command line client section above.
You can override these system properties by passing in their names and
values in the env map.
This is handy, as it means you can write a program with two clients,
each of which connects to different repositories, using different SSL
settings.
As you may have guessed, the command line client is just a very thin
veneer which calls the methods above, bundled into the API
.jar, accessed by its main method.
Web access
You can now
point your favorite web browser at http://localhost:6700/
or at http://localhost:6701/ to see the content within
each location.
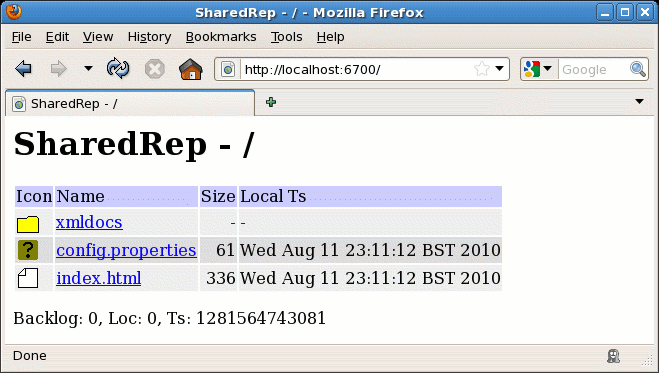
Human friendly directory listings are provided :-
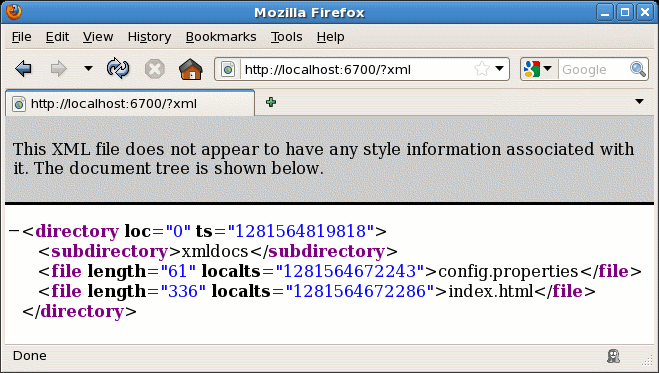
Or, XML style directory listings are provided, suitable for parsing using XPath :-
If the html or xml request parameter is
appended, this controls which kind of listing you get.
If neither is supplied, the listing will be HTML, unless the cluster
configuration includes dirListing=xml.
In the HTML listing, the Backlog number is an indication of how many fetches from remote locations this location knows it will have to do (or consider doing) before its copy of the repository can be considered up to date. Of course, this can only reflect information from the current set of locations in the cluster - there can be other fetches required from other locations not currently running or reachable.
In the HTML listing, the Loc number is the location number of the
repository you are fetching web pages from.
In the XML listing, this is the loc attribute of the root
<directory/> element.
In the HTML listing, the Ts number is the locations
cluster timestamp.
In the XML listing, this is the ts attribute of the root
<directory/> element.
In the HTML listing, the Local Ts column gives the most recent
file modification time as a local timestamp (shown in a textual form).
In the XML listing, this is the localts attribute of each
<file/> element.
A meta request suffix can be appended to return
some additional metadata with each file.
When returning file data, the web server deduces the mime type from
the file extension.
You can override this by appending a request parameter such as
mime=text/html.
Unfortunately, Internet Explorer doesn't always seem to pay attention to this.
Note that as per the content model, it is possible
for a given name to appear twice in a directory listing, once for a directory
and once for a file.
The HREF to the file does not end in / and
the HREF to the directory does end in /.
The web server is therefore able to decide whether to send file data
or directory listing, depending on which link you select.
You can arrange to be notified when files change. If the repository contains configuration data used by running processes, you might want to send the processes a SIGHUP or use a JMX method call, in order to tell those processes to reload their configuration from the repository.
Implement the following interface :-
//
// SharedRepTrigger.java - the interface to receive notifications
//
// Note that you are called "under-lock", which means that if you try to
// access the repository from these notification methods, you can hang.
// If you need to touch the repository in response to being notified,
// queue some work for another thread to do.
//
package nyangau.rep;
public interface SharedRepTrigger
{
public void init();
public void written(String name, byte[] b);
public void deleted(String name);
}
Then ensure the Shared Rep server loads your class using
Class.forName by putting your code on the classpath.
The Shared Repository can be made to instantiate an instance of your object
by using the -t command line argument.
The init method is called when the repository has initialised.
Due to the threaded nature of the code, this is not guaranteed to happen prior
to the first call to written or deleted.
If you had coded written and deleted to enqueue
work items, init would be a great place to fire up a thread
to consume from that queue.
Inside nyangau-rep.jar is a simple example, which can be
loaded using -t nyangau.rep.SharedRepTriggerSample.
As its in nyangau-rep.jar, its already on the classpath.
All it does is display messages to System.out.
Note particularly the comment about being under-lock.
Attempting to call into the repository will cause a deadlock.
Doing any lengthy processing will suspend repository internal processing
and also the servicing of client requests.
To handle this, queue an item of work on a
java.util.concurrent.BlockingQueue and have a thread
consuming and servicing them.
Because the written method supplies the new file content,
it is often unnecessary to use a queue and thread.
Do not modify the data passed in the byte[].
Note that you will not necessarily see every file state transition.
This is partially because of the distributed replication mechanism, and the
fact changes can be made anywhere.
All that can be promised is that the notifications that you do see which apply
to a given file are in the order that they occurred to that file.
Ordering of notifications between files are not preserved - ie: if F1 changes
then F2, you might see the notification for F2 before F1.
Essentially the notifications can be read as "the latest we know currently
is that the file content has changed to X".
If file content changes to C1, then C2, then C3, you might only see
written notifications for C1 and C3.
It is also possible to see deleted before written.
It is also possible to see deleted followed by
deleted.
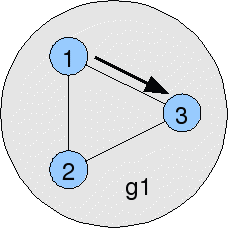
Replication groups
Replication groups are how you control what replicates with what. Here is a simple cluster configuration in which each location replicates directly with each other, and a change made in any location only has one hop to traverse to make it to another location (see arrow) :-
groups=g1 group.g1=1,2,3
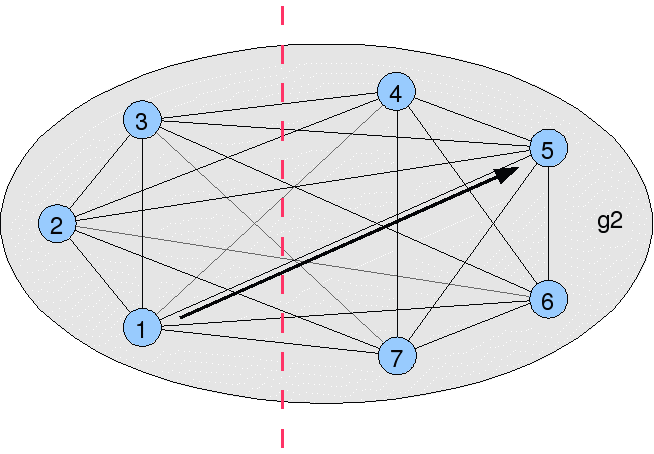
If we had 7 locations, 3 in America and 4 in Europe, we could prepare a cluster configuration in which each location replicates with every other, where a change only requires one hop to reach any other location. However, note that changes can cross the atlantic (red dotted line) 3 or 4 times :-
groups=g2 group.g2=1,2,3,4,5,6,7
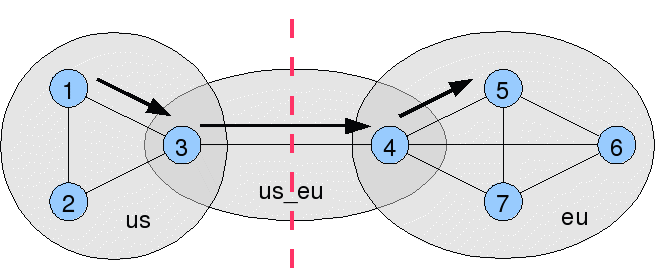
Using more than one replication group, we can use less than N*(N-1) connections between N locations. In the next cluster configuration, changes only cross the atlantic once, but a given change may have to go through 3 hops to reach certain locations (see arrows) :-
groups=eu,eu_us,us group.us=1,2,3 group.us_eu=3,4 group.eu=4,5,6,7
The example above turns locations 3 and 4 into single points of failure, so perhaps a hybrid solution is more appropriate. The configuration below removes the single points of failure, and changes only traverse the atlantic twice :-
groups=us,us_eu,eu group.us=1,2,3 group.us_eu=2,3,4,5 group.eu=4,5,6,7
Be careful not to split into seperate groups with no overlap. You would end up with two seperate sets of repository content :-
groups=eu,us group.us=1,2,3 group.eu=4,5,6,7
In summary: You have the flexibility to trade-off redundancy in routing
paths against network efficiency.
Cluster timestamps
The cluster timestamp used in each location is the sum of its
system clock and its location.N.tAdjust value.
Normally, location.N.tAdjust is 0, but it can be a positive
number of milliseconds.
Cluster timestamps are used to resolve conflicts between file updates in different locations, but of course, clocks are never exactly synchronized between locations.
It is important that cluster timestamps in different locations are close to each other.
Tip: You can easily get a view of cluster timestamp being used in a given location by fetching a directory listing from its web interface.
The problem: If location 1 is 3 minutes ahead of location 2, if a write happens to a file in location 1, and is followed by a write 1 minute later in location 2, this second write silently does not occur (because the first write has a later cluster timestamp).
For small skews like this, and for the use-cases Shared Repository is intended for, this is no big deal, just retry the write later. As the skew is small, this is not normally an operational problem. If clients in the locations don't talk to each other, they have no way to know which order the writes happened in anyway.
Large skews are more of a problem. If location 1 is an hour ahead of location 2, a write in location 1 cannot be overwritten by location 2 until an hour is passed. This is more of an operational issue, so clearly we don't want to allow skew to get large.
When one location attempts to connect to another location, if the cluster timestamps differ by more than 5mins, the connection is rejected and an error message logged.
If a cluster had 3 locations, and we knew the clock on location 2 was slow by 1 hour (compared to the real world clock), we could include the following in the cluster configuration :-
location.0.tAdjust=0 location.1.tAdjust=0 location.2.tAdjust=3600000
If location 2 was fast by 1 hour (compared to the real world clock), we would have to do this (ie: we'd have to catch the other locations up) :-
location.0.tAdjust=3600000 location.1.tAdjust=3600000 location.2.tAdjust=0
If you change any system clock, then you'll need to change the cluster configuration.
If a system clock is moved backwards in time, its
location.N.tAdjust value should have that number of
milliseconds added.
If a system clock is moved forwards in time, the
location.N.tAdjust value of the other locations should have
that number of milliseconds added.
The new cluster configuration file should be distributed to all locations.
Any location which has had its location.N.tAdjust changed
will need to be restarted.
The key things to bear in mind is that when modifying these numbers we want every locations cluster timestamps to be close to each other, and they must never go backwards.
Beware of suspend/resume when working with VMware and similar technologies. After resumption, the clock in the VM will be behind, and there many possible things the VM clock could do :-
You'd need to configure it so that the VM clock jumps to the present.
For VMWare, see
Timekeeping in VMware Virtual Machines, section
"Synchronizing Virtual Machines and Hosts with Real Time".
The .vmx file needs tools.syncTime = true,
and VMware Tools should be installed in the guest.
The fileModTs API on the SharedRepClient
class returns a local timestamp.
Specifically, it returns the cluster timestamp value actually associated
with the file in question, minus the local tAdjust value.
This is normally fine, but be advised that if the cluster configuration
is changed so that the local tAdjust value changes, files
will start reporting different modification times.
Logging
Shared Repository now uses java.util.logging.
A sample logging.properties is included which causes a
finer level of logging to be performed.
Activate by passing
-Djava.util.logging.config.file=logging.properties.
There are three loggers, called
nyangau.rep.Rep,
nyangau.rep.SharedRep and
nyangau.rep.SharedRepLocation.
SEVEREs are logged for serious environmental problems,
such as ParserConfigurationException.
WARNINGs are logged for things likely to be configuration
errors, such as authentication failures, or too large cluster timestamp
mismatches.
INFOs are logged for normal infrequent activity, such as
startup and connections being made and lost.
FINEs are logged for all the gory details of individual file
transfers between systems.
Monitoring
Shared Repository exposes the following MBeans :-
| ObjectName | Attribute | Meaning | |||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
nyangau.rep:type=SharedRep
|
There will only be SharedRepLocation entries for those
locations this location is in a replication group with.
Note that when this location makes a new connection to location N,
it cannot assume location N knows anything about this location,
so it will send all its metadata.
So Dirty will become as large as MapSize
and then decrease to zero as metadata is sent.
Note that when connectivity to another location is lost,
ConnectedInbound is likely to become false
immediately, but ConnectedOutbound could take a minute or so
to become false (ie: disconnection detected at next heartbeat).
If ConnectionNumberOutbound or
ConnectionNumberInbound keep incrementing, this can indicate
unstable network connectivity.
It can also indicate cluster configuration problems, such as mismatching
passwords and cluster timestamps being too far apart.
One mismatching cluster configuration problem is when the cluster configuration at location N includes a replication group with N and M, and yet the cluster configuration at location M doesn't have such a group. So N talks to M, and M says I'm not expecting to talk to you, and disconnects. Of course, this should never happen, as all locations should be using identical cluster configurations.
The nyangau.se Servlet Engine used within Shared Repository
also exposes a couple of MBeans.
Implementation
Rep manages a directory full of content in such a way as to ensure that all changes are atomic.
SharedRep keeps metadata in memory relating to the files that its local Rep has. It also publishes the same information to other locations it is connected to. A given SharedRep location connects to any other location that it is in a replication group with. Upon being notified of a later version of something in another location, it queues a request to fetch the remote content. Upon being notified of a later file deletion in another location, it can immediately delete the local version.
Server to server communication is over SSL. Connections used to replicate metadata are long lived, and one exists in each direction between each pair of locations. Each location pushes its changes to the other. In periods of no activity, heartbeats are sent to prevent firewalls terminating the connection.
When a location realises another location has a later version of some file data, it issues a fetch request for the data. This is a seperate connection specifically for fetching. The first fetch request makes a connection, but does not immediately close it when done. It hangs around for 10s, before being closed. If a subsequent fetch happens within the 10s, the existing open connection is reused. This improves performance by avoiding SSL handshaking and authentication and avoids connection failures caused by the OS not freeing up closed sockets for reuse quickly enough.
If a connection fails, the initiating location can retry.
Client to server communication is also over SSL. Just like server to server fetch requests, client to server connections are not closed immediately and are managed in a pool.
The HTTP interface is a servlet hosted in the nyangau.se
Servlet Engine, as found at
http://www.nyangau.org/.
Revision history
| Version | Date | Comments |
|---|---|---|
| 0.4 | 2010-05-23 | First public release. |
| 0.5 | 2010-06-16 | The servlet now correctly does a "send redirect"
for directory fetches not
ending in /.
Don't swallow IOExceptions in the
constructor, so you can see if your keystore
is missing.
Add a small number of JMX MBeans and pickup nyangau.se with JMX MBeans.
|
| 0.6 | 2010-07-05 | 2nd attempt at "send redirect" fix.
Extra Loc attribute on
SharedRepLocation MBeans.
|
| 0.7 | 2021-07-18 | Use java.util.logging.
Extra ConnectionNumberXxx attributes
on JMX SharedRepLocation MBeans.
Documentation of the content model. Clarify how xxxInDirectory works for
non-existent directories.
Extra command line client commands to cope when a file and a directory have the same name. Make web interface cope when a file and directory have the same name. Dramatically speed up command line client with lots of files in the repository. Pick up nyangau.se 1.3, which
doesn't decode URLs.
|
| 0.8 | 2010-08-11 | Added SharedRepClient constructor
with env map.
Added ChangeCount and
LastChangeTime MBean attributes.
Added init method to trigger
interface.
Added fileModTs method to return
modification time (local timestamp).
|
| 0.9 | 2014-12-12 | Now correctly HTML encodes repository filenames with special characters. HTML directory listings now consistently shows timestamps in human readable form (XML listings still show as milliseconds since epoch). |
| 1.0 | 2024-02-17 | Move to Java 11 and nyangau.se 3.0.
|
| future... | Cache XML content | |
I wrote all this code in my own time on my own equipment.
I used public non-confidential information to do so.
I hereby place all this code into the public domain.
Feel free to do whatever you like with it.
No copyright / no royalties / no guarantees / no problem.
Caveat Emptor!
Anyone offering ideas/code must be happy with the above.
Summary
The Shared Repository represents a very simple way to provide widely replicated content in an eventually consistent way.